On This Page
As a database administrator or ETL (Extract, Transform and Load) developer, there is a specific challenge you are destined to encounter at some point in your career while working with MS SQL server. In fact, it is quite likely that this has and will occur more than once, always seeming to catch one by surprise when least expected, resulting in software application or reporting server performance complaints.
What am I referring to? Long running code.
You may be asking what exactly is long running code? Long running code is simply SQL code that takes a long time to complete (or not complete), causing the server to run really slowly.
The scenario usually occurs when you develop your code on QA or a smaller data set and it works perfectly, as expected, but the performance rapidly changes for the worse once the software system moves over to Production or uses the full data set. This kind of performance degradation may also happen over time, after the database grows in size. Furthermore, long running scripts quite often have a negative impact on hardware running the SQL server, such as overutilizing the CPU, memory or disk, which is not good considering that the server needs to support other queries.
When SQL scripts run way longer than they should and cause servers to perform poorly, the question to be asked is “What is the root cause of the long running script?” Long running scripts are commonly caused by incorrect or missing indexes and SQL query design with table size and row count complicating matters further. To resolve these kinds of database problems requires:
- An evaluation of the server execution plan
- Identification of the code bottleneck
- Possible index creation/modification, and
- Possible modification of the SQL query
To illustrate some of these techniques, I’ve put together a modified real-life example where I successfully decreased the query runtime from 25min 7sec to 21 seconds (98% decrease) by following a 4-step process. Join me in showing you the steps I took while covering SQL server execution plans and query modifications to fix this long running script in the following example.
Example: Comparing Tables
Suppose you have two tables – a master table and comparison table.
You want to identify records where ProductId in the comparison table differs to ProductId in the master table for accounts that match between the 2 tables.
The primary attributes for matching the tables is AccountId or SubAccountId.
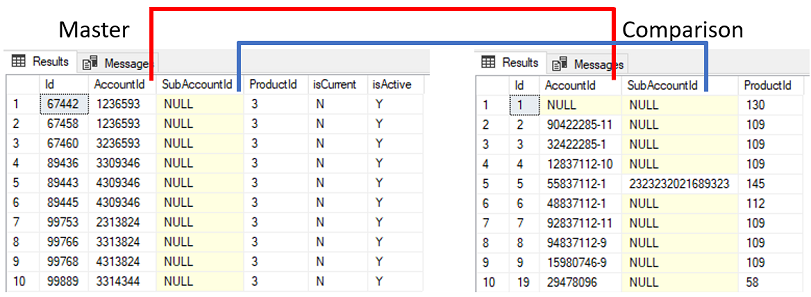
As can be seen above, the data quality isn’t great with many duplicate and null records in Master. The Comparison table does not contain any duplicate records where AccountId or SubAccountId is not null.
Further to this, the attribute isCurrent and isActive must both equal ‘Y’ in the master table as a condition for the records to be matched.
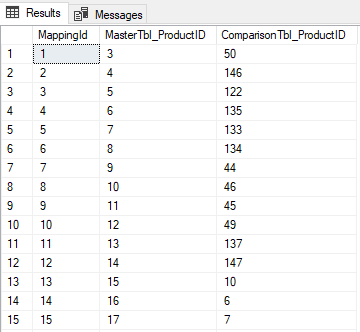
Another requirement is that a mapping table is required to match ProductId between the two tables since the ProductIds originate from different source systems-for example ProductId 3 in the Master table matches to ProductId 50 in the Comparison table.
Also to note in this example, the Master and comparison tables have both been created with a clustered index on the Id field. A clustered index defines how data is physically stored in a table and it is recommended that all tables have a clustered index for various performance reasons. Since the table data can only be sorted physically in one way, only one clustered index is allowed per table (the index can be a composite index comprising of more than 1 field).
Mapping table
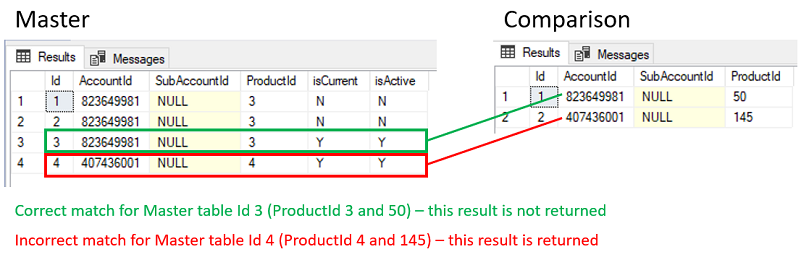
Applying the business logic above gives the following result where any returned records are classified as anomalies:
There are many possible SQL code solutions depending on your thought process but let’s say we create the following code to solve the problem:
Valid SQL code snippet
This code is simply a test for the 1st MappingId record to determine if our code logic works correctly. Since, during our test runs, this code runs in less than 1 second and returns the correct results, we deem the code to be satisfactory and proceed in finding a way to apply this code logic to the rest of the MappingIds (let’s say there are 52 of them).
We produce this code below which simply uses variable parameters to replace the literal valued MappingIds and ProductIds and inserts the results into a table.

You hit execute, grab a cup of great tea expecting the results to be complete in about a minute only to see that the query above is still running 20 minutes later. Since you know that Master contains only 479k records and Comparison contains far less at 27k, you begin to realise that by now the query should have completed.
So, what exactly is the problem? You may immediately be suspicious of the variable parameters we introduced since our test code ran in less than 1 second.
Step 1: Establish whether the SQL code still runs long with literal valued parameters
Is this problem related to parameter sniffing? Parameter sniffing generally means something smells funny and in the words of Brent Ozar “it’s not the elephant”. SQL server uses a process called parameter sniffing when it executes stored procedures that have parameters. When the procedure is compiled or recompiled, the value passed into the parameter is used to create a stored execution plan which is subsequently reused based on that initial value.
No, the problem isn’t related to parameter sniffing since we are not using a stored procedure but rather a transact SQL snippet.
After checking our results table by running a SQL code snippet to determine the last completed MappingId, we notice that the query seems to be stuck on MappingId 14. To solve this issue, we apply the following steps.
After 2 minutes the code above is still running – we recall that our initial test ran in less than 1 second for MappingId 1. At this point we know that the variable parameters are not at fault but rather something within the query.
Step 2: Review the execution plan and apply suggested indexes
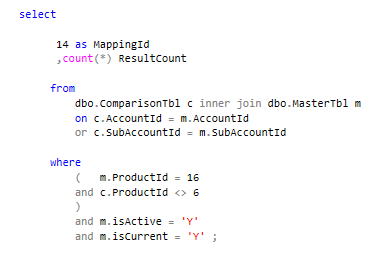
The initial ‘go to’ when trying to understand why a query runs long or inefficiently is generally the execution plan which is a graphical representation of various steps that is involved with fetching results from the database tables. Running an execution plan helps to quickly understand the performance of query. In SQL Server Management Studio (SSMS) you can hit Ctrl+L or click on the icon in the toolbar to “Display Estimated Execution Plan” for your query. When reading an execution plan, note documented steps such as loop, aggregate and scan as well as the cost percent. Retaining the literal valued parameters, we generate estimated execution plans for both queries (MappingId 1 & 14)
MappingId 1 Execution Plan
Query 1: Query cost (relative to the batch): 1%

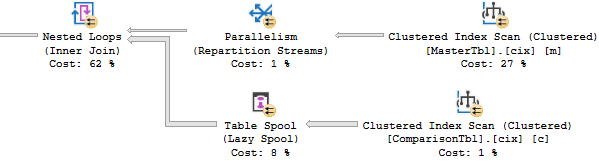
MappingId 14 Execution Plan
Query 2: Query cost (relative to the batch): 99%


You will notice that SQL server produces different execution plans for the same query based on the parameter values (3 & 50 in query 1 for MappingId 1 and 16 & 6 in query 2 for MappingId 14) which seems rather strange. Additionally, you will notice that even though we are evaluating the same query twice, the 1st query contributes only 1% of the overall cost while query 2 contributes 99% of the overall cost.
You will also notice that SSMS includes a missing index section per execution plan which is a great feature and is quite useful. The suggested query 1 & 2 index design is exactly the same.
The query 1 suggested index could improve the query cost by 23.23% while the query 2 suggested index could improve the query cost by 99.98%.


At this point a feeling of elation replaces any concerns over the long running query – a 99% increase will absolutely make that cup of tea far more enjoyable.
After applying the suggested index, the execution plans appear as follows:
Query 1: Query cost (relative to the batch): 1%


Query 2: Query cost (relative to the batch): 99%

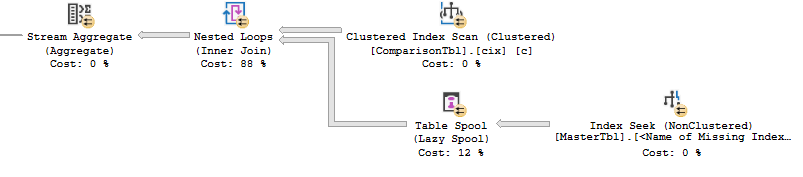
Reviewing the new execution plan for the long running query (2) yields an unexpected result – the new plan looks very similar to the old plan, except for the last step which is now a seek and no longer a scan (an improvement since seeks are faster than scans). At a guess this won’t really have any improvement since the last step accounts for 0% of the overall query 2 cost.
Executing query 2 only for the problematic MappingId 14 (there are still another 51 MappingIds) confirms that very little has actually changed. In fact, the query completes in exactly the same amount of time with the new index (2 min 16 seconds) while maxing the CPU at 100% for that period, as it did before the new index.
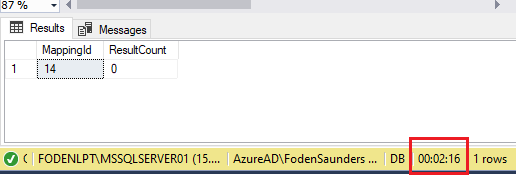
Step 3: Isolate the bottleneck
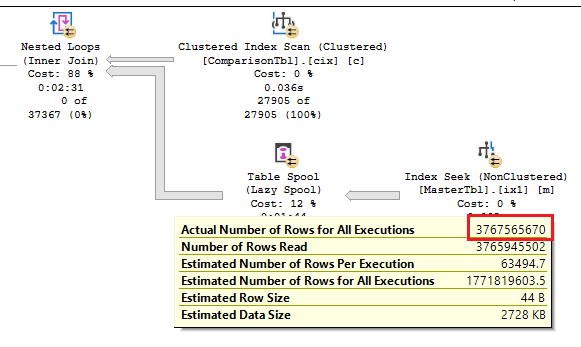
We know that 88% of the 2nd execution plan (which accounts for 100% of the cost between the 2 queries according to SSMS) is the highest cost and is linked to the Nested Loops operator. If we could somehow decrease this cost then our query should be less intensive and complete sooner.
What does a Nested Loops operator do? And why is it costing so much? Looking at the detail for this operator by hovering over the operator, we see that the predicate (or search criteria) is focussed on the inner join which includes an OR therein.
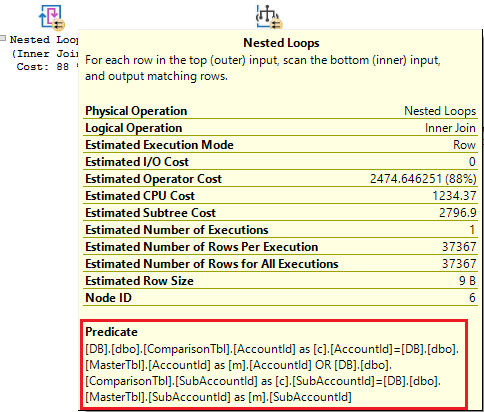
As a test, disabling the SQL query OR part of the inner join returns a complete result in less than 1 second and that is good and bad news! We now know which part of the query is taking a long time to run (good news) but the business rule is still applicable (bad news).
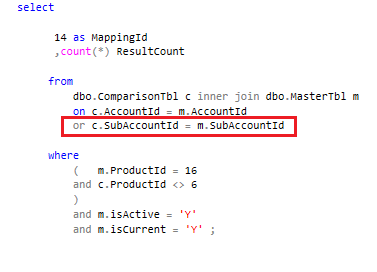
SQL server has chosen the Nested Loops operator to fulfil the inner join in our SQL query. If we drop the OR part of the join, SQL server utilises a Hash match (which is more efficient in this case).
Before solving the problem let’s have a look at how the Nested Loops operator works.
A Nested Loops operator joins data (utilizing a cross join) from two input streams and creates a single combined output stream.
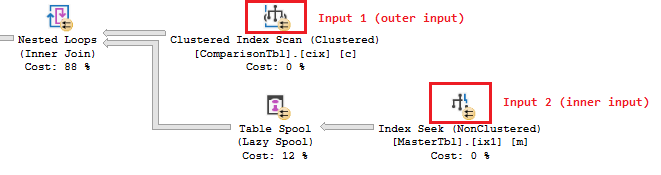
In this case our two input streams are the data from the Master (input 2) and Comparison (input 1) tables. Obtaining the data from ComparisonTbl is facilitated by a Clustered index scan (not dreadful but not a seek) and obtaining the data from MasterTbl is facilitated by an index seek (decent) but this is not the problem.
The problem occurs when the Nested Loops operator applies this logic as stated in the SSMS operator description “For each row in the top or outer input, scan the bottom or inner input, and output matching rows.”
What does that mean?
It means that a cross join is performed by the Nested Loops operator to fulfil our required inner join clauses. This is illustrated in the diagram below showing how every row from MasterTbl is compared against every row of ComparisonTbl (CPU intensive!)

Establishing what that would actually look like in our data, we apply the query logic individually to each table yielding the following record counts:
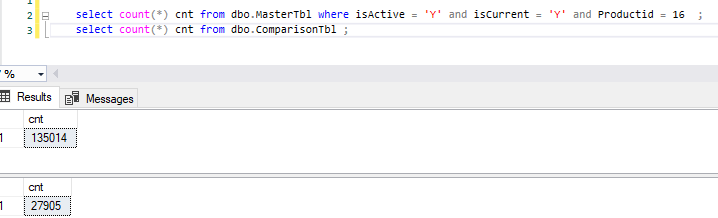
This would mean that the nested loops operator would need to read 3.7 billion rows in order to satisfy the inner join logic containing the OR clause! (27,905 x 135,014 = 3,767,565,670 rows) No wonder why this step was taking so long!
This is confirmed by the actual execution plan which shows that the nested loops operator read that exact number. This is only for MappingId 14 which is 1 of 52 MappingIds. This nested loop process needs to take place for the other 51 MappingIds.
Step 4: Modify the code
Now that we know which part of the code is running long, we can address the code by modifying it in a way that produces a more efficient execution plan, while retaining the required business rule logic.
Modified SQL query

We modified the query to include a union where the 1st part of the union joins on AccountId and the second part joins on SubAccountId.
Conclusion
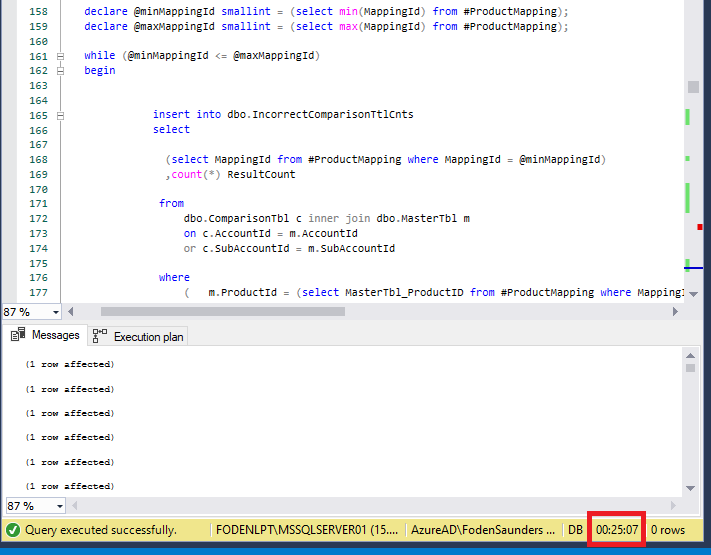
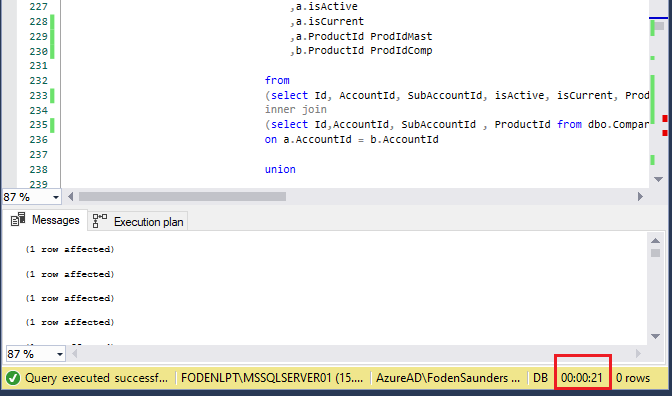
We successfully decreased the query runtime from 25min 7seconds to 21 seconds (98% decrease) by following the 4 steps above.
Before:
After:
Trying to explain to a client or employer why a query is running long can be tricky. There are a lot of technical aspects that are challenging to describe. And discovering the root cause requires detailed analysis. The truth is that SQL query optimisation and performance tuning is an important and realistic part of writing SQL code. At some point you are likely to come across this obstacle but thankfully a quick internet search on the topic will yield multiple online courses, books, videos and content to keep you busy for years.
Additional resources
More detail on Nested loops:
https://sqlserverfast.com/epr/nested-loops/
https://www.youtube.com/watch?v=0arjvMJihJo
Execution plan visual tool:
http://www.supratimas.com/webapp
SQL Server Execution Plans eBook:
https://www.red-gate.com/simple-talk/books/sql-server-execution-plans-third-edition-by-grant-fritchey/